Appearance
CS 336 Lecture 9: 缩放定律 1 (Scaling Laws 1)
缩放定律概述 (Overview)
缩放定律解决的核心命题
缩放定律(Scaling Laws)旨在回答一个极其务实的工程问题:如果我们拥有特定的计算资源,应该训练多大的模型,以及喂给它多少数据?
IMPORTANT
可预测性 (Predictability): Scaling Law 的核心价值在于,我们可以在小模型上进行参数微调和实验,通过拟合出的曲线预测大模型的性能,从而避免盲目在大规模训练上浪费算力。
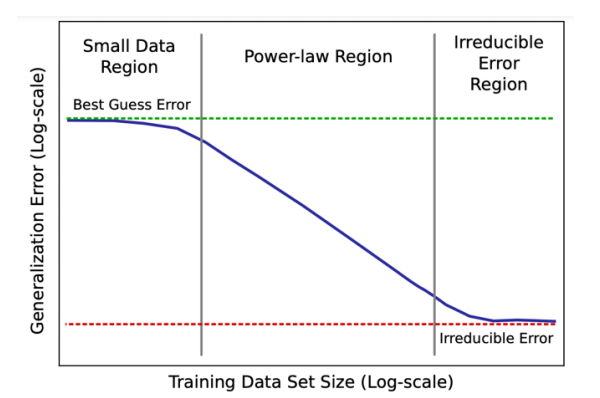
Scaling Law 的维度
我们在讨论缩放时,通常关注以下三个变量的相互制约:
- 计算量 (Compute, C):通常以 FLOPs 衡量。
- 数据量 (Dataset Size, D):训练使用的 Token 数量。
- 参数量 (Parameters, N):模型的尺寸。
数据缩放定律 (Data Scaling Law)
幂律分布与本征维度
研究表明,Loss 随数据量
- 本征维度 (Intrinsic Dimensionality):不同的任务(翻译、建模等)对应的指数
不同。这反映了数据的内在复杂度。 - 数据规模 vs 性能:是否存在简单的规则反映这种关系?目前公认在 Log-Log 坐标系下呈现线性关系。
数据配比的影响
TIP
斜率与截距: 改变数据的组成配比(Data Composition)通常只会影响截距,不会影响斜率。这意味着我们可以在小规模数据下寻找最优的数据混合比例(Data Mix),然后直接 scale 到大规模训练。
模型缩放定律 (Model Scaling Law)
架构与优化器的选择
- Transformer vs LSTM:实验证明 Transformer 的 Scaling 曲线显著优于 LSTM,且随着规模增大,差距越明显。
- AdamW vs SGD:在大规模训练中,AdamW 表现出更稳定的缩放特性。
- 深度 vs 宽度 (Depth vs Width):虽然两者都重要,但并非所有参数的价值都相等。在固定参数量下,存在最优的长宽比 (Aspect Ratio)。
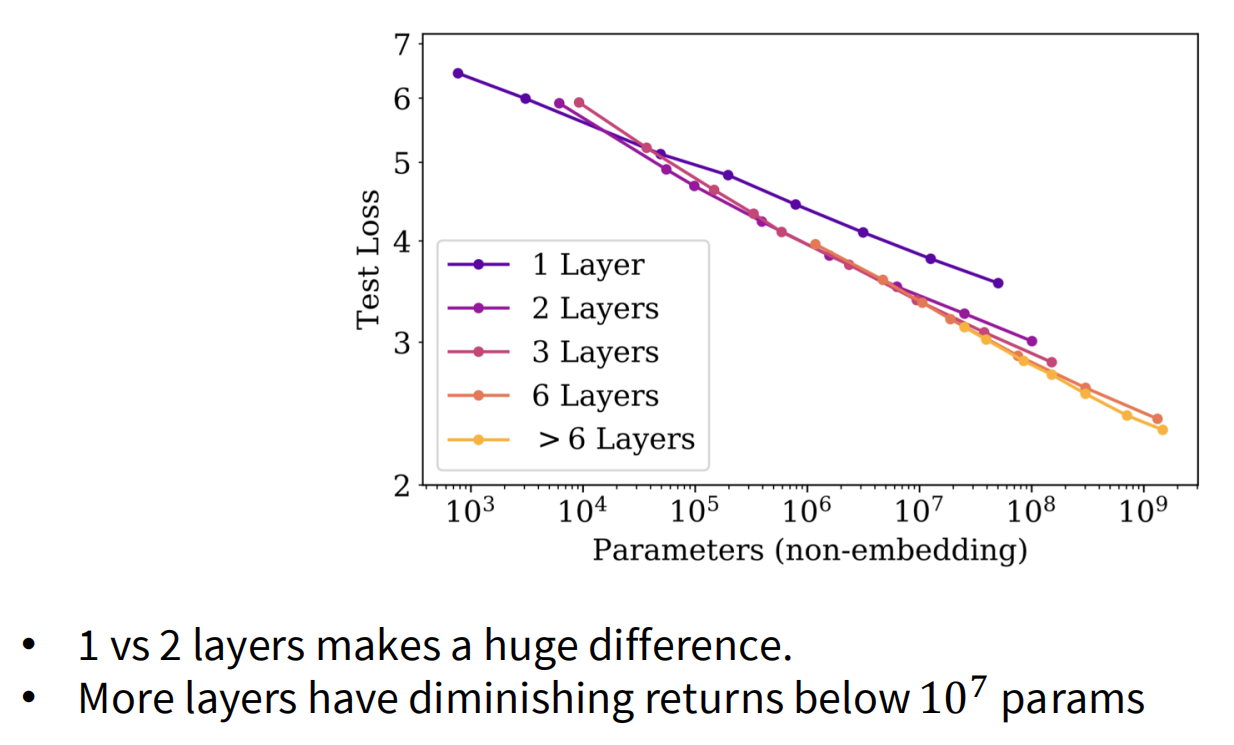
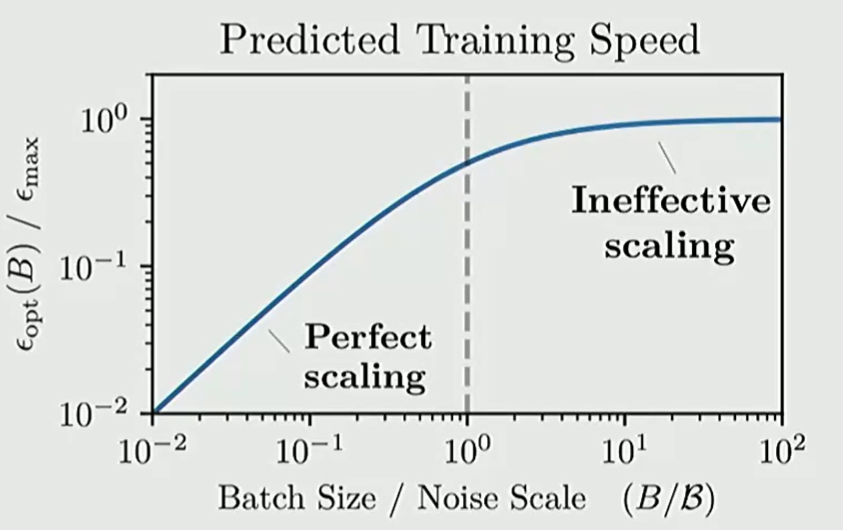
临界批大小 (Critical Batch Size)
IMPORTANT
收益递减点: 较大的 Batch Size 可以加速并行训练,但存在一个临界点。超过 Critical Batch Size 后,增加 Batch Size 对收敛速度的提升将不再明显(进入噪音主导区)。我们应在小规模实验中寻找该临界值。
数据-模型联合缩放 (Joint Scaling Law)
当模型大小
Kaplan vs Rosenfeld 公式
目前学界主要有两种拟合视角:
Rosenfeld+ (2020):侧重于可约误差。
Kaplan+ (2020, OpenAI):侧重于不可约误差。
WARNING
局限性: Scaling Law 主要适用于以 Log 为底的 Loss(如 Cross Entropy)。直接在下游 Benchmark 上验证 Scaling Law 可能会失效,因为下游任务通常存在“涌现”或非线性突变。
Chinchilla 比例与计算优化
Chinchilla Ratio: 1:20
DeepMind 在 Chinchilla 论文中指出,OpenAI 的 Kaplan 模型(如 GPT-3)属于 明显训练不足 (Under-trained)。
- 核心结论:模型参数
和训练 Token 数 应该等比例增加。 - 黄金比例:1 个参数 大约对应 20 个训练 tokens。
拟合方法论
为了得到最准确的缩放关系,Chinchilla 采用了三种实验方法:
mermaid
graph TD
A[Chinchilla Fit Methods] --> B[Minimum over runs]
A --> C[IsoFLOPs]
A --> D[Joint fits]
B --> B1[提取不同规模下的下包络线]
C --> C1[固定 FLOPs, 寻找 N 和 D 的最优配比]
D --> D1[基于网格搜索拟合三维 Loss 空间]- IsoFLOPs:这是最直观的方法,它回答了:“在给定的算力预算内,Loss 最低的点在哪里?”
- 推理成本的考量:现代模型(如 Llama)为了推理效率,往往会大幅超越 Chinchilla 比例,使用更多的 tokens 训练更小的模型(Over-training)。
